Since the dawn of the decade, the tech sector has witnessed unprecedented growth which led to a surge in salaries of technical talent, and mass-scale hiring. However, 4 years later, the tech industry faces immense challenges associated with hiring, and affording technical talent. According to Coderpad, an increasing number of organizations are hiring internationally, specifically rising from 41% to 51% in 2024. As a result, organizations are looking at outsourced providers to increase the size and diversity of their talent pool, and this is the most popular way to cast a wider net of talent.
Consequently, given the conditions of the tech industry, the Resource Augmented Model (RAM) stands out as an attractive strategy for organizations aiming to achieve sustainable growth and competitive advantage.
In short, resource augmentation lets you hire top tech talent on demand, boosting project agility and cost-efficiency. Resource Augmentation provides the most appropriate resources at the right time for immediate working with start-ups, mid-tier, and large enterprises and meeting all of your project objectives. This article examines why the resource-augmentation model makes business sense today, and why traditional hiring practices don’t provide a practical solution.
Why you Should Reconsider your Approach
Soaring Developer Salaries
If you’re a business owner, or a hiring manager looking to hire tech talent in 2024, this one might hit home. The pandemic induced a boom in tech, leading to an unprecedented salary rise. According to ADP, in 2019, the average base salary for a U.S. developer was $110K. By 2022, it grew to $120K, now at $130K. On average, developers earn 2x the median annual salary in the U.S.
Between 2018 and 2024, U.S. software developer base salaries increased by a larger dollar amount than average, But that’s because their baseline salary was higher than average to start.
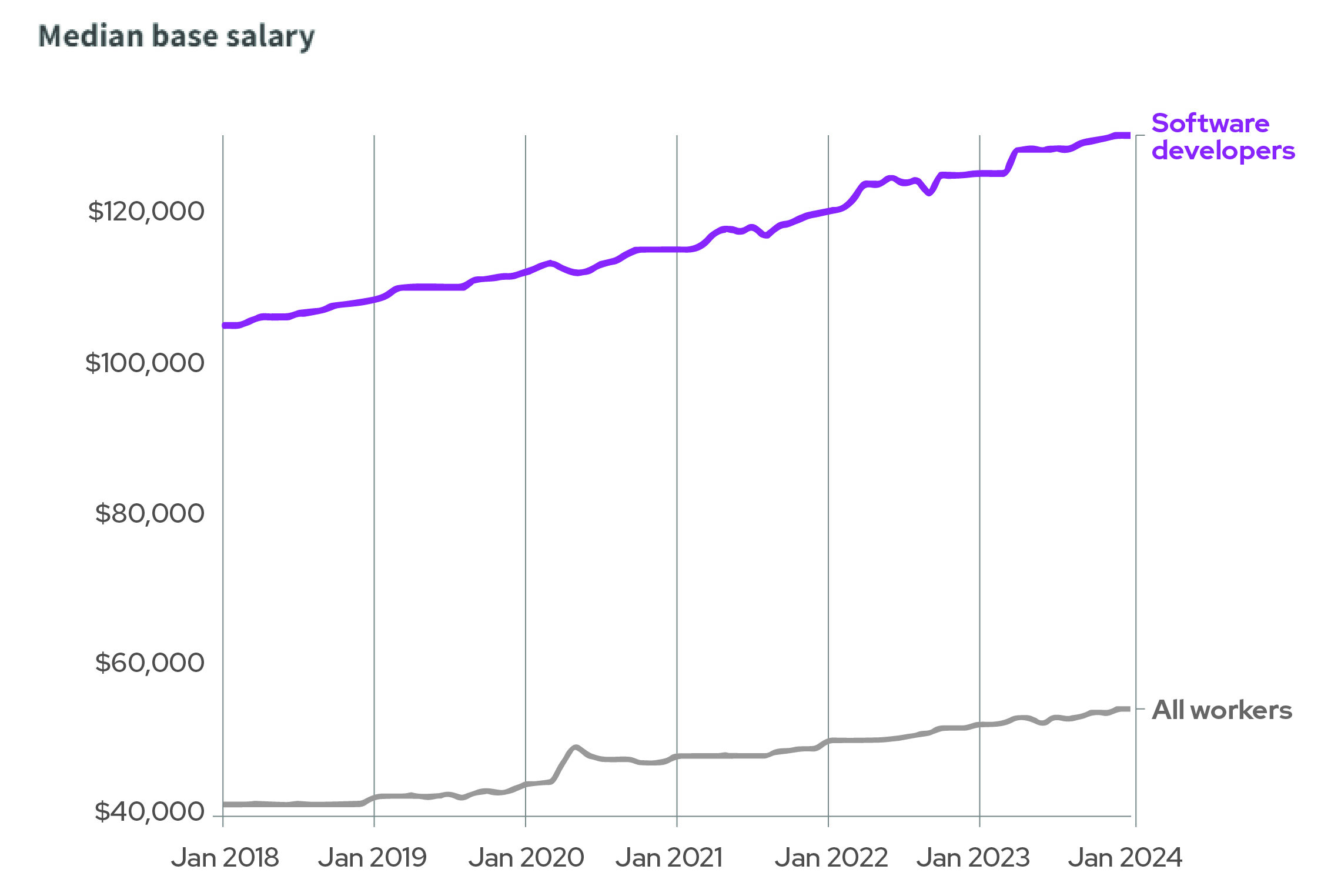
Source: ADP Research Institute
The increase in salaries for key developer roles is also highlighted in Stack Overflow’s latest Developer Survey. According to the data, in the United States, between 2022 and 2024, the average salary of a mobile developer grew at a CAGR of ~13%, while the average salary of a back-end developer grew at a rate of ~6.5%.
United States
| Role | 2022 | 2023 | 2024 | CAGR (%) |
| Developer, Mobile | $144,000 | $163,000 | $185,000 | 13.35% |
| Developer, back-end | $150,000 | $165,000 | $170,000 | 6.46% |
| Developer, full-stack | $140,000 | $140,000 | $135,000 | -1.80% |
| Developer, front-end | $133,000 | $140,000 | $135,000 | 0.75% |
| Project Manager | $140,000 | $125,000 | N/A | – |
| Developer, QA or Testing | $120,000 | $124,000 | $130,000 | 4.08% |
Source: Stack Overflow, Developer Survey.
Similarly, across the Atlantic, the German tech industry also saw an increase in salaries. According to Stack Overflow, the average salaries of mobile and back-end developers grew at a CAGR of ~7% between 2022 and 2023. The salaries for roles such as full-stack developer, and front-end developer also rose, albeit at a much slower rate than the rest.
Germany
| Role | 2022 | 2023 | 2024 | CAGR (%) |
| Developer, Mobile | $67,186 | $83,530 | $77,332 | 7.29% |
| Developer, back-end | $70,380 | $80,317 | $80,000 | 6.62% |
| Developer, full-stack | $66,708 | $69,608 | $70,000 | 2.44% |
| Developer, front-end | $63,986 | $68,537 | $66,615 | 2.03% |
| Project Manager | $70,380 | $80,317 | N/A | – |
| Developer, QA or Testing | $66,652 | $69,608 | N/A | – |
Source: Stack Overflow, Developer Survey.
United Kingdom
The U.K. has also fallen victim to rising developer salaries, and despite salaries across key developer roles slightly decreasing in 2023, largely driven the country’s poor economic performance, by 2024, the average cost of hiring a developer increased across the board. The average salary of a mobile developer increased by a CAGR of ~8% between 2022 and 2024, while back-end developer, and full-stack developer salaries grew by ~3%.
| Role | 2022 | 2023 | 2024 | CAGR (%) |
| Developer, Mobile | $87,948 | $99,311 | $101,910 | 7.65% |
| Developer, back-end | $87,948 | $89,379 | $94,267 | 3.53% |
| Developer, full-stack | $77,896 | $74,483 | $82,802 | 3.10% |
| Developer, front-end | $75,384 | $71,100 | $76,433 | 0.69% |
Source: Stack Overflow, Developer Survey.
Rising Hiring Costs
A recent study of global tech talent by the Linux Foundation found that over 95% of organizations view hiring technical talent important. However, technical recruiting poses a significant challenge. Moreover, 43% of organizations report high costs and long recruitment times, often without securing the ideal candidate. This can lead to project delays (38%) and difficulty verifying claimed skills (37%).
According to 43% of respondents, recruitment is costly, time consuming, and often does not lead to the right candidate
What are the main challenges to hiring technical staff?

Source: Linux Foundation, 2024
Similarly, a study by Pluralsight in 2024 revealed that the costs associated with filling an open position are staggering. Imagine a vacant technologist role with an average salary of $90,000. Considering they contribute 3x of their salary in value, a nine-week search to fill the position translates to a missed opportunity cost of $65,423. In total, the study by Pluralsight found that the average cost of hiring new tech talent in the U.S. is $23,450, and is £32,178 (per employee) in the U.K.
Longer Hiring Cycles
Technical recruiting remains a formidable challenge for organizations, with 43% citing its costliness, time-consuming nature, and frequent failure to find suitable candidates as primary concerns. Delving deeper into the duration of the hiring process; the Linux Foundation revealed that organizations spend an average of 5.4 months on recruitment, with 64% taking over four months to fill open positions. Particularly concerning is the trend indicating a lengthening hiring process compared with 2023, with an average time of 4.6 months.
On average, how long does it take to hire a headcount to fill an open technical position in your organization?
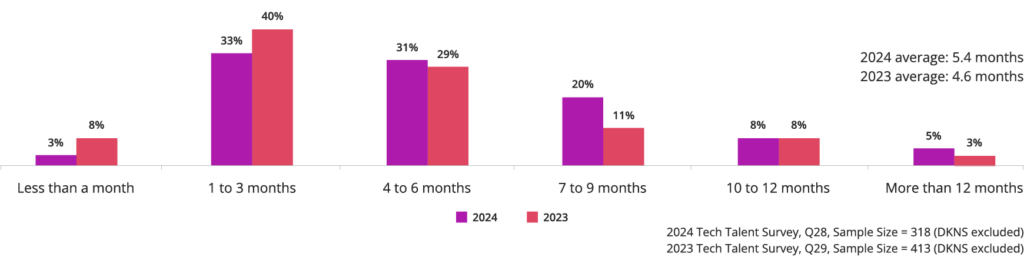
Source: Linux Foundation, 2024.
Analysis across different technical roles reveals consistent timelines, with executive management roles requiring the longest recruitment periods, averaging 6.2 months, followed by AI/ML engineers and SRE/platform engineers. Conversely, front-end/back-end developers and network administrators generally have shorter hiring periods.
About how long does it take to hire a headcount to fill an open position in your organization for the following technical roles?
| Role | Average time to hire (months) |
| Executive Management | 6.2 |
| Al/ML Engineer | 6.1 |
| SRE / Platform Engineer | 6.0 |
| Project Manager | 5.9 |
| Data Analyst / Scientist | 5.9 |
| Systems Administrator | 5.9 |
| IT Management | 5.9 |
| Data Management | 5.8 |
| Role | Average time to hire (months) |
| DevOps / DevSecOps / GitOps | 5.8 |
| Cloud Architect / Engineer | 5.8 |
| Security Professional | 5.6 |
| Front-end / Back-end developer | 5.5 |
| Network Administrator | 5.3 |
| Systems Administrator | 5.9 |
| IT Management | 5.9 |
| Data Management | 5.8 |
Source: Linux Foundation, 2024.
Growing Preference for Hybrid/Remote Work
The onset of the pandemic changed the way the tech sector worked, and caused a drastic shift in the psyche of employees in the sector. Remote and distributed work is no longer a perk, it is considered essential. This is reflected in the numbers published by Stack Overflow’s 2023 Developer Survey. They discovered that currently, ~88% of developers work in a remote environment, with 44% working fully remotely. However, some companies are now mandating that their staff come back into the offices full time, which hasn’t gone down too well with everyone. But this mandate might lead to significant ramifications such as employees leaving their jobs for companies that offer the flexibility of remote work.
A survey from FlexJobs found that 63% of people say “having remote work” is what’s most important to them in a job, even ahead of salary (61%), having a flexible schedule (55%), work-life boundaries (54%), or having a good boss (48%). Additionally, 63% of working professionals are willing to take a salary cut to work remotely, with 17% stating they would take a 20% decrease in salary. Finally, a survey from Spiceworks discovered that 78% of job seekers plan to apply for remote roles, highlighting the desire for ongoing flexible work schedules.
As shown in the image below, the distributed model is not going away. The Harvard Business Review projects that by 2030, the distributed model (i.e., hybrid and remote work) will account for more than a quarter of an average organization’s full-time employees.
What share of your firm’s full-time employees are in each category?
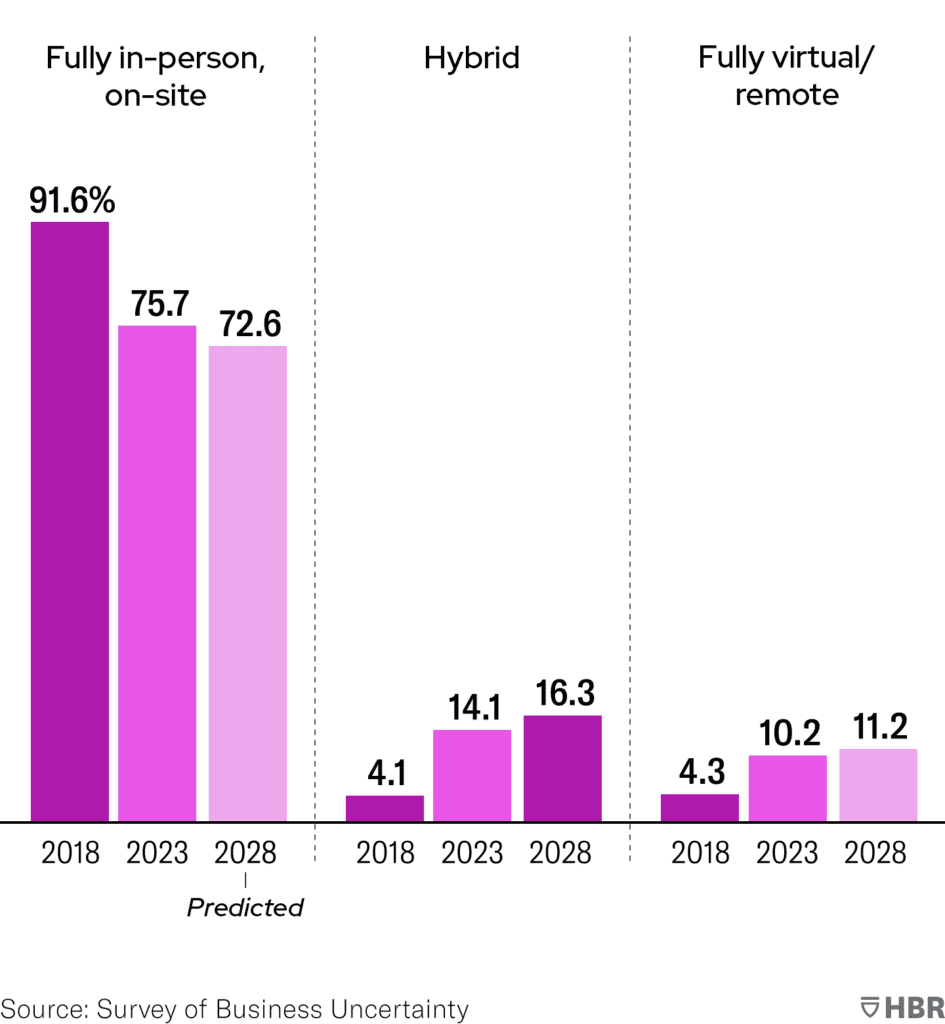
Source: Harvard Business Review, 2023.
Growing Employee Demands
As Maslow said, employees are complex because their motivations and satisfaction are influenced by various factors across security, social, self esteem etc. which must be addressed to foster engagement, productivity, and loyalty. This statement rang true then and still rings true today. Beyond their monthly/annual remuneration, tech employees have a growing list of demands that they want to be fulfilled. These demands play a substantial role in influencing their decision on where they want to work. These expectations also significantly influence an employee’s motivation and engagement.
Benefits That Are Important to Tech Professionals

Source: Dice, 2024.
As shown in the image above, health insurance, PTO, 401k matching and pension benefits remain most important to tech professionals. While the share of those claiming these benefits as important has trended downward over the past few years, tech workers regard them as the most important. A study from AON found that average costs for U.S. employers that pay for their employees’ health care will increase 8.5% to more than $15,000 per employee in 2024.
Moreover, the data indicates a huge disparity between the benefits tech workers want and the ones they have. For example, while 53% of tech workers report that they want a work-from-home stipend, only 19% have it. There are similar gaps in benefits such as stock programs, training and education, commuter assistance, and dependent care. The information suggests that costs associated with providing benefits, motivating and engaging their employees will only continue to rise, placing substantial cost pressures on Executives across organizations.
When to use Resource Augmentation?
Rapid Team Scaling
In today’s fast-paced business world, companies often need to rapidly grow their development teams to keep up with sudden project demands or seize new opportunities. The Resource Augmentation Model (RAM) makes this possible by allowing businesses to quickly bring in additional developers with the right skills. This is especially helpful for startups or companies in expansion mode, where getting to market quickly is critical.
Access to Specialized Skill Sets
Sometimes, a project requires specialized expertise in areas like AI, machine learning, cybersecurity, or blockchain technology. RAM helps businesses tap into a pool of experts with these niche skills, without the need for long-term hires or extensive training.
Managing Variable Workloads
Workloads in software development can be unpredictable, with big spikes during new feature rollouts, product launches, or major updates. RAM offers the flexibility to scale up resources when needed and scale down when things calm down. This not only optimizes resource use but also keeps costs in check, as businesses only pay for the extra help when it’s required.
Short-term Projects and Prototypes
For short-term projects like prototypes or Minimum Viable Products (MVPs), RAM is a perfect fit. It allows companies to bring in the expertise they need for a limited time, ensuring the project’s success without the commitment of full-time hires. This is particularly useful for innovation labs and R&D departments that work on exploratory projects with uncertain outcomes. By using RAM, businesses can speed up development and have more room to experiment and innovate.
Cost Management and Budget Flexibility
Managing costs is always a top priority, and RAM offers a cost-effective solution. By turning the fixed costs of full-time employees into variable costs, businesses can better manage their budgets. This model is especially beneficial for companies with fluctuating project demands, as they only pay for resources when needed. This financial flexibility helps maintain stability and ensures that budgets are used wisely.
Addressing Talent Shortages
In areas where there’s a shortage of skilled software developers, RAM provides a practical solution by opening access to a global talent pool. This approach helps businesses overcome local talent shortages, keeping development projects on track without delays. It also brings a diverse range of skills and perspectives to the team, leading to more innovative and resilient solutions.
Case Study: Driving Nelly.com’s Success with the Resource Augmentation Model
Fast fashion e-commerce thrives on marginal gains—whether it’s a faster website, a more immersive shopping experience, or a smart recommendation engine, every detail counts in encouraging customers to complete their purchases. Recognizing this, Nelly.com, one of the largest online fashion retailers in the Nordics, sought a software engineering partner that could not only help them stay ahead of competitors like Amazon but also work closely with their in-house team while focusing on long-term product goals. Nelly turned to Calcey, leveraging the Resource Augmentation Model to achieve these objectives.
Calcey’s partnership with Nelly began with an integration of Nelly’s in-house developers into Calcey’s team. This close-knit collaboration led to the overhaul of Nelly’s critical backend systems, making them future-proof and scalable. Together, the teams; built Nelly’s Android mobile app from the ground up, ensuring it was fast, data-efficient, and featured new functionalities like a ‘Swipe Feed’ to enhance user engagement. Additionally, the team developed innovative solutions such as a ‘nice price’ module to provide accurate pricing information based on exchange rates and customs duties, improving the overall customer experience.
“We needed a partner where we had the possibility of scaling the number of resources we needed up and down. We also wanted a partner with a wide skill set so that we can draw on backend developers one day and app developers the next day, for both iOS and Android apps, which we are using today.” — Henrik Palmquist, Former CTO, Nelly.com
The collaboration between Calcey and Nelly has yielded tremendous results. Beyond just technical improvements, Calcey took ownership of maintaining Nelly’s mobile apps, internal software, and other web properties, including NLYMAN.com. The success of this partnership is evident in Nelly’s growth, with the company reporting net sales of nearly SEK 1.3 billion in 2020, despite global economic challenges
This case study exemplifies how the Resource Augmentation Model can deliver significant value, allowing companies like Nelly to scale their development capabilities and achieve sustained growth in a competitive market.
Conclusion
In conclusion, as more employees prefer remote work and the costs of hiring and retaining tech talent continue to rise, it is becoming increasingly challenging for organizations to meet these demands. The Resource Augmentation Model emerges as a standout solution, offering a cost-effective way to acquire skilled developers and scale development efforts. With established companies specializing in this model, it provides a viable path for organizations to enhance their capabilities and stay competitive in the global market.
Calcey is a Gartner-recognized, boutique technology consulting and software product engineering provider, known for rapidly launching products to market tailored approach. We excel in total project ownership, offering a complete range of services from design to development. Specializing in the Resource Augmented Model, we integrate specialized talent into your teams, ensuring flexibility, cost efficiency, and high-quality delivery to meet the demands of complex projects, across several industries such as e-commerce, media, healthcare, fintech many more!