
DreamStart Labs (DSL) is a fintech with a social mission. Their main product, ‘DreamSave’, is a free app designed to simplify the management of savings groups in unbanked communities of developing countries. These individuals often find themselves excluded from conventional credit systems due to their inability to meet traditional creditworthiness standards.
The DreamSave application bridges this gap by helping users conduct meetings, handle financial records, reach savings targets, and establish credit histories. With every new user, DreamSave moves one step closer towards its goal of eradicating poverty and empowering community banks and savings groups.
The Initial Version of DreamSave
The first version of DreamSave was created as a Minimum Viable Product (MVP) to explore this concept of digitizing savings groups. The MVP was beta tested in four South African countries to validate the product offering. During this phase, the DreamSave engineering team identified the MVP’s limitations and bottlenecks. They also pinpointed specific areas that needed improvement to provide users with more features and benefits. The beta phase was a success as the application quickly garnered significant traction within these communities. The ability to no longer be tied down to paper trails and physically manage your savings group was groundbreaking and adoption was quick towards the DreamSave app.
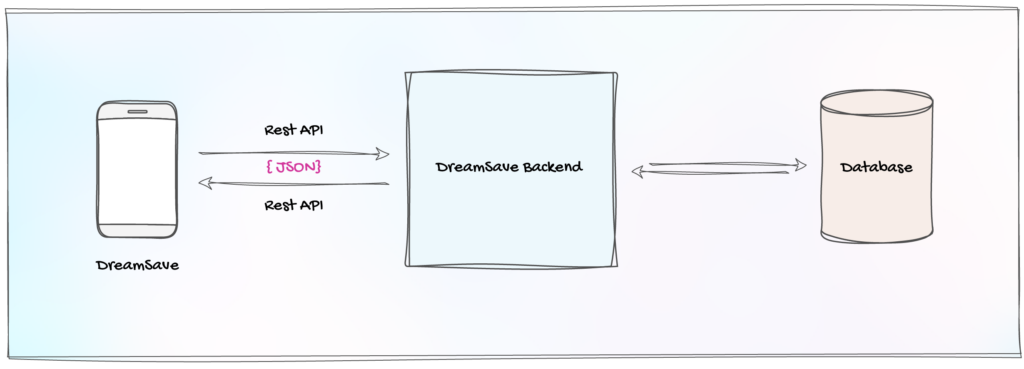
Figure 1: DreamSave MVP High-Level Architecture
As shown in the diagram above, the DreamSave backend is a monolithic application developed in Java Spring Boot. It offers a JSON-based REST API that fuels the DreamSave mobile application. All incoming API requests are handled synchronously, and internal data processing is handled asynchronously using separate threads and stored in a single database.
This architecture facilitates vertical scaling, but given our ambitious expansion goals, we recognized the need to ensure that DreamSave 2.0 could also scale horizontally, enabling us to efficiently manage demanding workloads in a distributed manner.
Dream Save 2.0
At this juncture, it became evident that the concept of digitizing community-based savings groups had garnered significant traction. With the tremendous success of DreamSave 1.0, a multitude of strategic partnerships with NGOs were on the table and plans were in place to extend DreamSave’s reach from four to twenty different counties to serve more users.
The MVP proved that the idea was valid and it was now the time to scale the product to greater heights. DreamStart Labs acknowledged that the initial MVP was insufficient for this expanded scale of operations and carried technical debt. Recognizing the need for a capable software development partner, DSL sought to build a more robust version of their product to take it to market. This led to a collaboration with Calcey, where the decision was made to completely rebuild the DreamSave Platform. The primary focus was on enhancing security, scalability, and high availability, crucial elements to support their ambitious expansion plans.
Design Goals of DreamSave 2.0
The team learned a great deal from DreamSave 1.0. They then embarked on a ground-up re-engineering of the solution, focusing on adhering to the highest architectural standards. After many sit downs with the client and our internal teams, the following key functional and non-functional requirements were identified as key to the larger solution.
- Offline Capability: DreamSave primarily serves users in remote areas with limited connectivity and expensive mobile data. To address these challenges, DreamSave 2.0 is designed to function seamlessly without an active internet connection. It automatically syncs data to the cloud in the background when a connection is available, ensuring uninterrupted usage even offline.
- Traceability and Compliance: In a data-driven FinTech product like DreamSave, understanding the reasons behind data changes is vital. Instead of storing only the final data state, DreamSave 2.0 maintains a comprehensive log of all events or actions that lead to data modifications. This approach enables detailed ‘time-travel’ through data, particularly valuable for advanced use cases like auditing.
- Reduced Mobile Data Usage: Mobile data costs are significant in our target markets. DreamSave 2.0 focuses on minimizing mobile data consumption, aiming for a 60% reduction on data sync compared to the MVP version to ease the financial burden on users.
- Faster Data Synchronization: Our beta testing revealed that over 90% of users operate the application offline, with short online intervals. To maximize these online moments, we aim to significantly enhance data synchronization speed, targeting a 40% improvement over the MVP version on a standard 4G mobile data connection.
- Near-Real-Time Data Processing: Once data is synchronized to the cloud, the data is readily available to be viewed by its members. Additionally, computationally intensive operations are performed to generate advanced business analytics. DreamSave 2.0 ensures seamless scalability, offering near-real-time access to these analytics on our dashboards, irrespective of data volume.
- Backward Compatibility: Despite a new data model, DreamSave 2.0 is committed to migrating existing data to the new version. We made it easy for all existing users to transition to DreamSave 2.0, enabling them to retain their data with a single button click.
By addressing these requirements with empathy towards our target audience, we ensured that DreamSave 2.0 was geared for success.
Design and Technology Selection Process
Optimizing HTTP Request Payload Size
In designing DreamSave 2.0, our primary objective was to ensure full functionality even in the absence of an internet connection. The model achieves this by locally storing data on the device until an active internet connection becomes available for seamless data transfer to the cloud. During the initial beta testing phase, it became apparent that a savings group comprising 30 members required approximately 12 to 13 megabytes to upload a single meeting to the cloud. With the average group conducting four meetings per month, this translated to an accumulation of approximately 50+ megabytes. These findings raised concerns, particularly in consideration of our user base and the mobile data landscape in our target markets. Consequently, the engineering team recognized the need to optimize communication between DreamSave 2.0 application and the backend servers.
After a thorough investigation, the team identified the following areas for improvement:
- Payload Structure Optimization: In the MVP version of DreamSave, a JSON-based REST API powered the mobile application. It was evident that the HTTP request payloads could be further simplified by eliminating redundant information to reduce the overall payload size. However, the benefits of this optimization did not meet our expectations.
- Adoption of Alternative Data Formats: As an alternative to the JSON format used in the MVP, the team conducted an evaluation of other options and identified Google Protocol Buffers as an ideal replacement for JSON. Protocol Buffers, developed by Google, provide a language-neutral, platform-neutral, and extensible method for serializing structured data. After several experiments, it became clear that protobuf messages were approximately 30% smaller than JSON, as they use a binary format for data serialization.
Beyond the efficiency and compactness of the Protobuf format, the team considered its support for a broader range of data types and the utility of schema enforcement in creating a future-proof and maintainable product. This played a pivotal role in the decision to implement Protobuf in DreamSave 2.0.
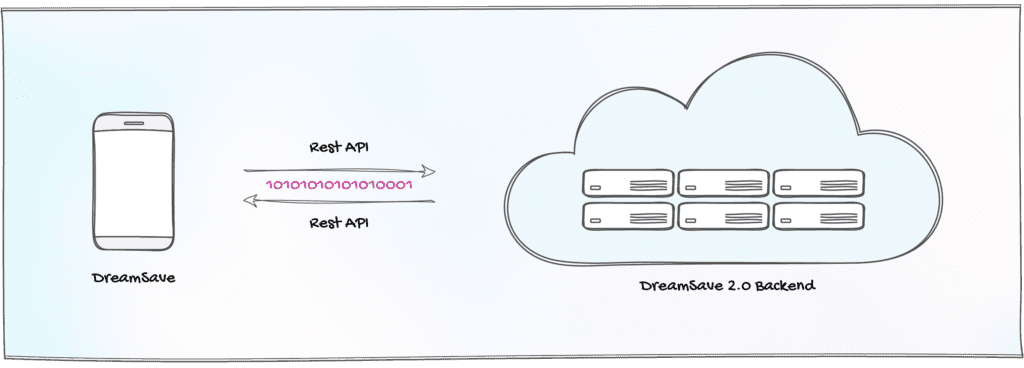
Figure 2: Utilizing Protocol Buffers in DreamSave 2.0
As depicted in the diagram above, DreamSave 2.0 utilizes a REST API to enable communication between the backend servers and the mobile application. The data payloads for the HTTP requests are serialized using Protocol Buffers.
Preserving Data Histories with Event Sourcing
During the design phase of DreamSave 2.0’s architecture, the engineering team intentionally chose to build it in a way that would support the preservation of the business context or the narrative behind each data point or state change within the system. For instance, when a customer’s name changes from “John” to “Mark”, it’s not enough to merely store “Mark”. The system should retain the knowledge that this name transitioned from “John” to “Mark” at any point in the future. This requires going beyond storing only the current state of the data. To fulfill this requirement, the team opted to incorporate the Event Sourcing pattern into DreamSave 2.0. The Event Sourcing pattern defines an approach to managing data operations driven by a sequence of events, each of which is logged in an append-only event store. The application code generates a series of events that explicitly describe each action taken on the data and records these events in the event store. In practical terms, when a data change occurs in a domain, it’s unnecessary to transmit the entire domain entity across the network. Instead, only the specific change is transmitted as an individual event, significantly reducing mobile data usage by minimizing the request payload size.
Furthermore, the adoption of the Event Sourcing model offers additional advantages that can prove invaluable in advanced use cases:
- Time Travel through Data: It enables the ability to traverse event streams in any direction for advanced analysis.
- Drive Business Intelligence: The system retains the business context, allowing for deeper insights.
- Improved Data Integrity and Auditability: Thanks to the immutable nature of Event Sourcing, data remains complete, secure, and readily auditable.
Given these advantages and benefits, the team made a deliberate choice to adapt the Event Sourcing pattern in DreamSave 2.0.
Achieving High Throughput and Low Latency with Backend APIs
A fundamental role of DreamSave 2.0’s backend is to facilitate the seamless synchronization of data with the cloud via its APIs. Considering the application’s offline-first approach, our engineering team understood the critical importance of prioritizing high throughput for write operations over read operations within the backend API. To ensure independent scalability, high availability, and simplified maintenance, the team chose to incorporate the CQRS (Command and Query Responsibility Segregation) pattern in the architectural design of the DreamSave 2.0 backend.
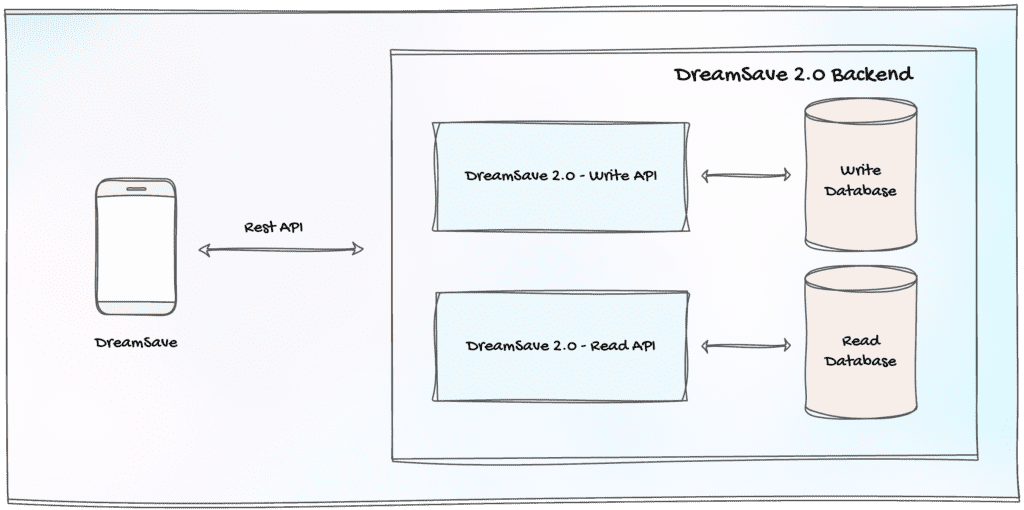
Figure 3: DreamSave 2.0 Backend Using Separate Read and Write APIs
The diagram above visually illustrates how the DreamSave 2.0 backend incorporates the CQRS pattern, employing distinct APIs for managing read and write operations. Additionally, the adoption of separate databases provides flexibility in utilizing specific database engines (whether NoSQL or SQL) while optimizing schemas, rather than adhering to a one-size-fits-all database engine or schema. This architectural approach promotes a loosely coupled system, enabling individual APIs to scale independently and efficiently handle high throughput.
The design decisions discussed above play a pivotal role in the development of high-throughput APIs. However, the team also recognizes that network latency is a distinct concern that warrants separate consideration, especially in the context of the deployment architecture. The final section of this article delves into this aspect, providing comprehensive insights into the overall architectural justification.
Real-Time Data Processing and Data Projections
As previously discussed in this article, the Event Sourcing approach revolves around managing data operations through a sequence of events, meticulously logged in an append-only event store. Retrieving the current state of a specific domain involves replaying all events associated with that domain from the beginning. While this approach offers numerous advantages, as outlined earlier in this article, there are specific use cases, particularly those involving advanced aggregate queries, where adopting a normalized, relational database is more practical.
In such scenarios, diverse data projections can be created based on the events stored in the event store. The creation of projections involves extracting the current state of a domain from an event stream. In the context of DreamSave, our team recognized the need for two primary projections:
- Extended Event Log Projection from the Main Event Store: This projection encompasses all events from the primary event store and includes additional events generated by the system based on specific business logic. The DreamSave 2.0 application predominantly relies on this data model, as it uses the Event Sourcing model to synchronize data with the cloud.
- Normalized Relational Read Model: This projection stores data in a normalized relational database, offering robust support for advanced queries. Data within this model consistently represents its current state at any given point, eliminating the need for replay operations when accessing data. This data model is used to share data with external entities through DreamSave Developer APIs.
As events are received by the backend, they are written into the Event Store. However, simply storing these events is insufficient—they must be processed in the exact same order to construct the projections. This is where the need for an event processing platform comes into play. After evaluating various options, the team opted to adapt Apache Kafka to manage event processing within the DreamSave 2.0 backend. Apache Kafka was selected for its proven stability and its support for distributed data processing.
Bringing It All Together
As the team set out to design DreamSave 2.0, they carefully considered the design objectives mentioned earlier. Following numerous iterations and in-depth design discussions, the team arrived at the following design:
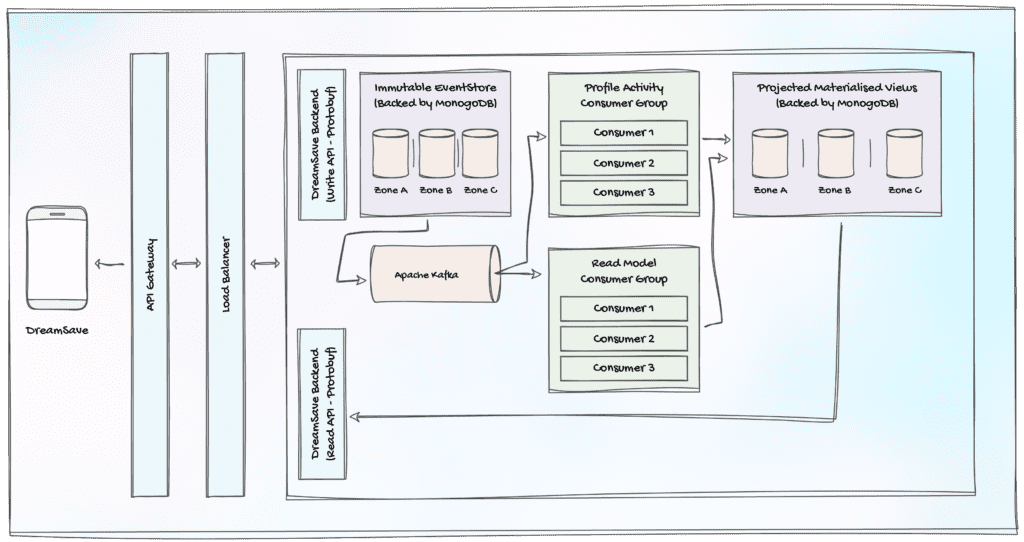
Figure 4: DreamSave 2.0 High-Level Backend Architecture
In the architectural diagram above, we illustrate how all DreamSave 2.0 APIs are exposed to the external world through an API gateway, complemented by a load balancer to efficiently distribute traffic across multiple backend instances. An essential feature of this setup is that the API strictly accepts Protocol Buffers, optimizing data exchange.
The backend of DreamSave 2.0 adheres to the CQRS pattern, treating the Read and Write aspects as distinct components. On the Write side, all incoming events are instantly written to an immutable EventStore, backed by MongoDB. Concurrently, these events are pushed to a single Kafka topic, initiating the processing and construction of the required data projections. Kafka guarantees the order of the events only within the same topic, and when it comes to Event Sourcing, the order of the events is crucial. This is why all events are published to a single topic with a specific partition key.
Data integrity is a central concern in our system. To support this, the team recognized that writing events to the Event Store and publishing events to Kafka should occur as an atomic operation. This is achieved through the execution of both operations within a single distributed transaction.
Another notable design element is the immutability of the Event Store, which simplifies event caching. With no need for cache invalidation, significant performance gains are realized. DreamSave 2.0’s backend leverages a distributed cache backed by Redis to further optimize operations.
Multiple Kafka consumer groups are subscribed to the single Kafka topic where all events are published. These consumer groups are responsible for processing incoming events and constructing the necessary data projections. In the context of the DreamSave 2.0 backend, two primary consumer groups stand out: the Profile Activity Consumer Group, tasked with building the Extended Event Log, and the Read Model Consumer Group, responsible for creating the Normalized, Relational data model. Both of these materialized views are written into a PostgreSQL relational database, ensuring optimized data retrieval for the read API.
To minimize network latency, the system can be deployed in multiple geographic locations, although this can be costly. Alternatively, CDNs can be utilized, but their performance shines best with static content. Our engineering team sought to reduce the latency of the sync API while keeping costs manageable. To achieve this, DreamSave 2.0’s backend relies on the Google Edge Network Point of Presence (PoP).
When a request is made to the DreamSave 2.0 API, the traffic flows directly from the user’s network and enters Google’s network at an edge Point of Presence (PoP) close to the user’s location. It then continues to use Google’s internal backbone to reach the virtual machine (VM) hosted on Compute Engine. This approach significantly reduces the network latency of the APIs by reducing the Time to First Byte (TTFB).
Recognition and Awards
Good product engineering is all about empathizing with how people actually go about their day-to-day lives. That is what DreamSave 2.0 went out to achieve and our efforts have been recognised.
DreamSave’s impact on the world has resulted in a slew of awards including:
- The Best Finance App and Best Developing World Technology award at the Fast Company 2023 World Changing Ideas Competition
- The Best Digital Banking Technology Award at the 2023 Worldwide Finance Awards
- The Most Empowering Digital Banking Technology Award at the 2022 Worldwide Finance Awards
In addition, DSL has partnered with AB Bank Zambia and BRAC Bangladesh to provide access to digital financial services and secure small business loans.
While it feels great to be part of a venture which has grown steadily over the years (Since 2020, DreamSave has facilitated more than 2.4 million transactions in 21 countries), it’s even more heartwarming to see how our work is making a positive impact in the lives of many. And that feeling…is priceless💜.
To learn more about our work with DreamStart Labs read our case study: https://calcey.com/work/dreamstart-labs/